Eric Muller
2003-09-18 20:31:51 UTC
1. What is encoded by the sequence of characters
U+1004 င MYANMAR LETTER NGA
U+1039 ◌္ MYANMAR SIGN VIRAMA
U+1004 င MYANMAR LETTER NGA
is it kinzi + consonant NGA or consonant NGA+ subscript consonant NGA?
Should we add some words to Table 10.3 to clarify that?
2. Does consonant + subscript consonant NGA ever appear? If so, how is
it rendered? If not, should we remove U+1004 from the third row of Table
10.3?
3. About Table 10.3: it is true that *in the encoding model* a cluster
is always made of one element of each row, with row 2 (consonant)
mandatory and the other rows optional?
4. Is that model realistic, or are there some exceptions, that is real
life situations that it does not capture? Of cases where the encoding is
possible, but not intuitive (e.g. two clusters in the encoding instead
of one)?
5. Is is "correct" to view the kinzi as a medial form of NGA, which just
happens to be encoded at the front of the cluster? For what values of
"correct"?
6. Finally, I have tried to encode various strings I have seen in print
(or rather as pictures of printed stuff). I would really appreciate if
somebody could check my encodings. By the way, I found the introduction
to the Burmese script on that site very interesting. In particular, not
having to consider encoding made the presentation more accessible (i.e.
it provides the level of expertise needed to understand the "Composite
Characters" subhead in section 10.3).
Thanks,
Eric.
Loading Image...
U+1018 MYANMAR LETTER BHA
U+102C MYANMAR VOWEL SIGN AA
U+1015 MYANMAR LETTER PA
U+1039 MYANMAR SIGN VIRAMA
U+101B MYANMAR LETTER RA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1010 MYANMAR LETTER TA
U+102C MYANMAR VOWEL SIGN AA
U+101C MYANMAR LETTER LA
U+1032 MYANMAR VOWEL SIGN AI
U+0020 SPACE
U+1001 MYANMAR LETTER KHA
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1017 MYANMAR LETTER BA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+102C MYANMAR VOWEL SIGN AA
U+1038 MYANMAR SIGN VISARGA
Loading Image...
U+1019 MYANMAR LETTER MA
U+102C MYANMAR VOWEL SIGN AA
U+1010 MYANMAR LETTER TA
U+102D MYANMAR VOWEL SIGN I
U+1000 MYANMAR LETTER KA
U+102C MYANMAR VOWEL SIGN AA
Loading Image...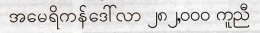
U+1021 MYANMAR LETTER A
U+1013 MYANMAR LETTER DHA
U+1031 MYANMAR VOWEL SIGN E
U+101B MYANMAR LETTER RA
U+102D MYANMAR VOWEL SIGN I
U+1000 MYANMAR LETTER KA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1012 MYANMAR LETTER DA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+101C MYANMAR LETTER LA
U+102C MYANMAR VOWEL SIGN AA
U+0020 SPACE
U+1042 MYANMAR DIGIT TWO
U+1048 MYANMAR DIGIT EIGHT
U+0020 SPACE
U+1042 MYANMAR DIGIT TWO
U+002C COMMA
U+1040 MYANMAR DIGIT ZERO
U+1040 MYANMAR DIGIT ZERO
U+1040 MYANMAR DIGIT ZERO
U+0020 SPACE
U+1000 MYANMAR LETTER KA
U+1030 MYANMAR VOWEL SIGN UU
U+100A MYANMAR LETTER NNYA
U+102E MYANMAR VOWEL SIGN II
Loading Image...
U+1021 MYANMAR LETTER A
U+1039 MYANMAR SIGN VIRAMA
U+101D MYANMAR LETTER WA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+101C MYANMAR LETTER LA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1038 MYANMAR SIGN VISARGA
U+1017 MYANMAR LETTER BA
U+102E MYANMAR VOWEL SIGN II
U+1007 MYANMAR LETTER JA
U+102C MYANMAR VOWEL SIGN AA
U+101C MYANMAR LETTER LA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+1039 MYANMAR SIGN VIRAMA
U+101F MYANMAR LETTER HA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1000 MYANMAR LETTER KA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1014 MYANMAR LETTER NA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
Loading Image...
U+1010 MYANMAR LETTER TA
U+102D MYANMAR VOWEL SIGN I
U+101B MYANMAR LETTER RA
U+1005 MYANMAR LETTER CA
U+1039 MYANMAR SIGN VIRAMA
U+1006 MYANMAR LETTER CHA
U+102C MYANMAR VOWEL SIGN AA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1025 MYANMAR LETTER U
U+101A MYANMAR LETTER YA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+102C MYANMAR VOWEL SIGN AA
U+1025 MYANMAR LETTER U
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1018 MYANMAR LETTER BHA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1037 MYANMAR SIGN DOT BELOW
U+0020 SPACE
U+2018 LEFT SINGLE QUOTATION MARK
U+1015 MYANMAR LETTER PA
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1012 MYANMAR LETTER DA
U+102C MYANMAR VOWEL SIGN AA
U+1014 MYANMAR LETTER NA
U+102E MYANMAR VOWEL SIGN II
U+2019 RIGHT SINGLE QUOTATION MARK
U+0020 SPACE
U+101B MYANMAR LETTER RA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1000 MYANMAR LETTER KA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
---
------------------------ Yahoo! Groups Sponsor ---------------------~-->
KnowledgeStorm has over 22,000 B2B technology solutions. The most comprehensive IT buyers' information available. Research, compare, decide. E-Commerce | Application Dev | Accounting-Finance | Healthcare | Project Mgt | Sales-Marketing | More
http://us.click.yahoo.com/IMai8D/UYQGAA/cIoLAA/8FfwlB/TM
---------------------------------------------------------------------~->
To Unsubscribe, send a blank message to: unicode-***@yahooGroups.com
This mailing list is just an archive. The instructions to join the true Unicode List are on http://www.unicode.org/unicode/consortium/distlist.html
Your use of Yahoo! Groups is subject to http://docs.yahoo.com/info/terms/
U+1004 င MYANMAR LETTER NGA
U+1039 ◌္ MYANMAR SIGN VIRAMA
U+1004 င MYANMAR LETTER NGA
is it kinzi + consonant NGA or consonant NGA+ subscript consonant NGA?
Should we add some words to Table 10.3 to clarify that?
2. Does consonant + subscript consonant NGA ever appear? If so, how is
it rendered? If not, should we remove U+1004 from the third row of Table
10.3?
3. About Table 10.3: it is true that *in the encoding model* a cluster
is always made of one element of each row, with row 2 (consonant)
mandatory and the other rows optional?
4. Is that model realistic, or are there some exceptions, that is real
life situations that it does not capture? Of cases where the encoding is
possible, but not intuitive (e.g. two clusters in the encoding instead
of one)?
5. Is is "correct" to view the kinzi as a medial form of NGA, which just
happens to be encoded at the front of the cluster? For what values of
"correct"?
6. Finally, I have tried to encode various strings I have seen in print
(or rather as pictures of printed stuff). I would really appreciate if
somebody could check my encodings. By the way, I found the introduction
to the Burmese script on that site very interesting. In particular, not
having to consider encoding made the presentation more accessible (i.e.
it provides the level of expertise needed to understand the "Composite
Characters" subhead in section 10.3).
Thanks,
Eric.
Loading Image...

U+1018 MYANMAR LETTER BHA
U+102C MYANMAR VOWEL SIGN AA
U+1015 MYANMAR LETTER PA
U+1039 MYANMAR SIGN VIRAMA
U+101B MYANMAR LETTER RA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1010 MYANMAR LETTER TA
U+102C MYANMAR VOWEL SIGN AA
U+101C MYANMAR LETTER LA
U+1032 MYANMAR VOWEL SIGN AI
U+0020 SPACE
U+1001 MYANMAR LETTER KHA
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1017 MYANMAR LETTER BA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+102C MYANMAR VOWEL SIGN AA
U+1038 MYANMAR SIGN VISARGA
Loading Image...

U+1019 MYANMAR LETTER MA
U+102C MYANMAR VOWEL SIGN AA
U+1010 MYANMAR LETTER TA
U+102D MYANMAR VOWEL SIGN I
U+1000 MYANMAR LETTER KA
U+102C MYANMAR VOWEL SIGN AA
Loading Image...

U+1021 MYANMAR LETTER A
U+1013 MYANMAR LETTER DHA
U+1031 MYANMAR VOWEL SIGN E
U+101B MYANMAR LETTER RA
U+102D MYANMAR VOWEL SIGN I
U+1000 MYANMAR LETTER KA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1012 MYANMAR LETTER DA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+101C MYANMAR LETTER LA
U+102C MYANMAR VOWEL SIGN AA
U+0020 SPACE
U+1042 MYANMAR DIGIT TWO
U+1048 MYANMAR DIGIT EIGHT
U+0020 SPACE
U+1042 MYANMAR DIGIT TWO
U+002C COMMA
U+1040 MYANMAR DIGIT ZERO
U+1040 MYANMAR DIGIT ZERO
U+1040 MYANMAR DIGIT ZERO
U+0020 SPACE
U+1000 MYANMAR LETTER KA
U+1030 MYANMAR VOWEL SIGN UU
U+100A MYANMAR LETTER NNYA
U+102E MYANMAR VOWEL SIGN II
Loading Image...

U+1021 MYANMAR LETTER A
U+1039 MYANMAR SIGN VIRAMA
U+101D MYANMAR LETTER WA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+101C MYANMAR LETTER LA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1038 MYANMAR SIGN VISARGA
U+1017 MYANMAR LETTER BA
U+102E MYANMAR VOWEL SIGN II
U+1007 MYANMAR LETTER JA
U+102C MYANMAR VOWEL SIGN AA
U+101C MYANMAR LETTER LA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+1039 MYANMAR SIGN VIRAMA
U+101F MYANMAR LETTER HA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1000 MYANMAR LETTER KA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1014 MYANMAR LETTER NA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
Loading Image...

U+1010 MYANMAR LETTER TA
U+102D MYANMAR VOWEL SIGN I
U+101B MYANMAR LETTER RA
U+1005 MYANMAR LETTER CA
U+1039 MYANMAR SIGN VIRAMA
U+1006 MYANMAR LETTER CHA
U+102C MYANMAR VOWEL SIGN AA
U+1014 MYANMAR LETTER NA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1025 MYANMAR LETTER U
U+101A MYANMAR LETTER YA
U+1039 MYANMAR SIGN VIRAMA
U+101A MYANMAR LETTER YA
U+102C MYANMAR VOWEL SIGN AA
U+1025 MYANMAR LETTER U
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1018 MYANMAR LETTER BHA
U+102F MYANMAR VOWEL SIGN U
U+102D MYANMAR VOWEL SIGN I
U+1037 MYANMAR SIGN DOT BELOW
U+0020 SPACE
U+2018 LEFT SINGLE QUOTATION MARK
U+1015 MYANMAR LETTER PA
U+1004 MYANMAR LETTER NGA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
U+1012 MYANMAR LETTER DA
U+102C MYANMAR VOWEL SIGN AA
U+1014 MYANMAR LETTER NA
U+102E MYANMAR VOWEL SIGN II
U+2019 RIGHT SINGLE QUOTATION MARK
U+0020 SPACE
U+101B MYANMAR LETTER RA
U+1031 MYANMAR VOWEL SIGN E
U+102C MYANMAR VOWEL SIGN AA
U+1000 MYANMAR LETTER KA
U+1039 MYANMAR SIGN VIRAMA
U+200C ZERO WIDTH NON-JOINER
---
------------------------ Yahoo! Groups Sponsor ---------------------~-->
KnowledgeStorm has over 22,000 B2B technology solutions. The most comprehensive IT buyers' information available. Research, compare, decide. E-Commerce | Application Dev | Accounting-Finance | Healthcare | Project Mgt | Sales-Marketing | More
http://us.click.yahoo.com/IMai8D/UYQGAA/cIoLAA/8FfwlB/TM
---------------------------------------------------------------------~->
To Unsubscribe, send a blank message to: unicode-***@yahooGroups.com
This mailing list is just an archive. The instructions to join the true Unicode List are on http://www.unicode.org/unicode/consortium/distlist.html
Your use of Yahoo! Groups is subject to http://docs.yahoo.com/info/terms/